For so many people, myself included, 2018 was a frenetic year; I worked with customers in many fields, from national and local government to defense and from healthcare to finance and everything in between, so I thought I’d share some observations.
This list below is in no order and I somewhat apologize for
the broad generalizations!
Everyone’s moving to the cloud
Every customer I worked with last year is either deployed on
Azure or going through the planning process. This is great to see, but it does
create some pain. Engineering staff must learn new skills (but that’s a good
thing) and old assumptions and ideas need casting aside in favor of new
technologies and deployment scenarios.
If you have no experience with cloud technology, then do
yourself a professional favor and get a free Azure
subscription and build something simple. If you have even an ounce of
intellectual curiosity you will be wildly excited at what you see and the
possibilities cloud-based solutions offer. You will also learn very quickly
that there’s a lot you do not know and even more you don’t know you don’t know!
The “WE-CANNOT-DEPLOY-TO-THE-CLOUD-BECAUSE-IT-IS-NOT-SECURE”
days are behind us. The emotion is gone, and people look to the cloud with a
more level-headed approach.
As a side note and example case-in-point; I was onsite with
a customer recently and on one of their sprint planning boards was a proposed
story about “making sure we have the Kubernetes fix for CVE-2018-1002105 is deployed.”
I asked the woman who wrote the story what was behind this story because we had
fixed the problem within 24 hours in AKS (Azure Kubernetes Services) and all
customers needed to do was roll their clusters. She told me she knew that Azure
and AWS had both fixed the issue quickly, but that’s wasn’t the problem. The
problem was they were grappling with their on-prem Kubernetes instances!
Q.E.D!
Crypto-agility
No-one is doing it. Ok, one customer I worked with is doing
it. In fact, this one customer is actively pursuing crypto-agility and
embracing it whole-heartedly. Said customer and I have regular meetings to go
over their current ideas for crypto-agility to make sure they have no missed
something.
Crypto-agility is the ability to change crypto (algorithms, key sizes, padding mode etc.) in an app without having to change the application code and still provide compatibility with data protected using older crypto. In other words, the crypto algorithm policy is separate from the code. Products like Microsoft SQL Server and Microsoft Office are great examples of different approaches to crypto-agility.
You can read more on the topic here.
Injection vulns are dead! Long live injection vulns!
I think I saw one genuine SQL injection vulnerability last
year in customer code. I saw a few examples of string concatenation to build
SQL statements, but the source data was from a trusted source. I still made the
customer change the code! So that’s good, right? I mean, a few years ago I’d
see dozens of SQLi bugs. The problem I saw was an uptick in other injection
vulns, such as XML External Entity (XXE) issues and people treating JSON data
like it’s trusted!
The adage that “incoming data is evil until proven
otherwise” is as true today as it was in 2002 when David LeBlanc and I wrote
Writing Secure Code (feeling old, yet?)
Folks are logging into Azure as Owner
You know that idiom of not logging on as an admin or as
root? Same applies to logging into Azure. Once you have configured the subscription(s)
you should not logon as an Owner, rather you should logon with lower privilege
accounts or use RBAC roles to restrict who can do what to what. That’s a
discussion for another day, but for the most part you really don’t need to use
the Azure Portal as Owner once the system’s running, rather you use scripts; any
and all Owner access is for “Break Glass” scenarios only.
Compliance is Huge
We all know that Compliance != Security. News outlets are
replete with stories of compromised HIPAA and HiTRUST compliant health care
institutions. Ditto PCI DSS and merchants. But there is an overlap between
Security, Privacy and Compliance and compliance dollars can be used to help
drive security programs. What I am trying to say is if you need to drive
security programs consider dropping the word “compliance” in your financial
requests and co-opt the compliance dollars. Just sayin’! It’s worked for me and
I will leave it at that!
By the way, find some time to look at the new
public preview for ISO27001, SOC and PCI compliance reporting in
Azure Security Center.
Customers are finally building Threat Models
There are no words to explain how happy I am to say this,
but every customer I worked with in 2018 understood the value of threat models
and have built threat models. Most importantly, the threat models helped drive
changes in their architectures and that’s fantastic!
Talking of compliance, there’s a relationship between threat
models and compliance programs, but I have a blog post already in the works on
that topic!
Devs and IT finally started talking to each other
A few years ago, I made a comment that “In a Cloud-First world,
devs have to learn basic networking and, networking folks need to learn basic
coding.” I stand behind that comment to this day. I saw this become a reality
last year. Devs now write code and deployment scripts that configure CIDR
blocks and VNets with help from the Networking team. And the Networking guys
and gals are doing likewise. All of sudden a networking person who does not
understand, say, JSON, Python and PowerShell will be irrelevant quickly! Same
holds for devs, they need to know what it means to put their app in VNet and wrap
a Network Security Group (NSG) around it and so much more.
Again, “In a Cloud-First world, devs have to learn basic
networking and, networking folks need to learn basic coding.” Ignore this
advice at your peril!
Azure Policy is fantastic and many people don’t know it’s there
I plan to cover this topic in much more detail in future,
but Azure Policy is fantastic and let me explain by way of example.
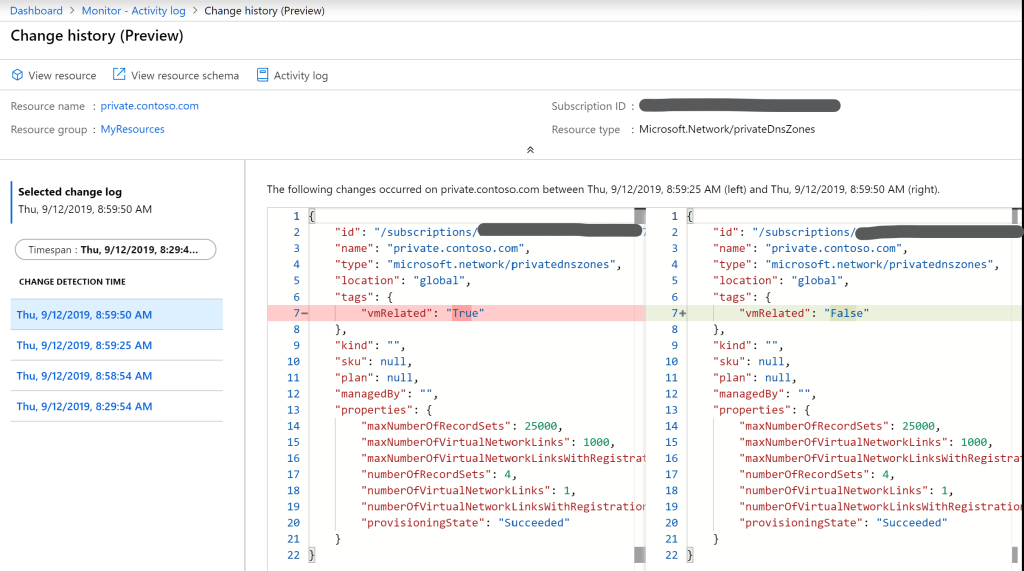
A financial customer I work with is interested in using CosmosDB and one of the nice features of CosmosDB is how easy it is to replicate data to other data centers around the globe. You can define geography, consistency rules and other transactional semantics at the click of a button. Want data in Australia so it’s closer to your antipodean clients? Just click on the data center(s) in Australia and that’s it!
One of the architects at the customer said, “That’s cool, but problematic because of data sovereignty issues and let’s not get started with GDPR!” I told him to not worry because we can enforce the allowable data centers through Azure Policy. The policy is defined in JSON (the syntax does take a little getting used to, however) and you can apply the policy in the Policy blade in the Azure Portal if you wish, or push it using any of the various scripting interfaces.
I created a quick-n-dirty policy that only allowed the US South Central and US East data centers.
I waited a few minutes for the policy to deploy and then tried to replicate data to Germany in the Portal. No dice! I then tried to replicate to Germany from a Python script. Nope! Finally, I tried Az CLI. Negative. In all examples, the policy intervened and blocked the attempt to replicate data to Germany.
The really nice thing about policy is there are numerous
outcomes of a policy violation, but the most common are “Audit” and “Deny” – I
won’t insult your intelligence by explaining what they do.
Azure Policy can apply to just about anything in Azure:
- Do you require only HSM-backed keys in Azure Key
Vault? Policy can do that.
- What about VMs never have a public endpoint? Got
that too!
- TLS required to blob storage? Got you covered!
I could keep going, but I think you get the picture.
You can learn more about Azure Policy here and there’s a GitHub repo of sample policies here.
Everyone has stickers on their laptops
Ok, this is not security, it’s just an observation. Says he
with a bunch of Ninja Cat and Azure stickers on his Surface Pro!
Wrap Up
To wrap up, 2019 is shaping up to be another amazing and
busy Azure year for my colleagues and I. I might even do a “Halfway through
2019 Retrospective” because there is so much going on in security and in Azure!