Before I get started, I’d like to thank Andrei Popov who is the main schannel developer and Candace Jackson who works on the TLS team. Without their help, I would have struggled to put this post together. Also, thanks to my colleague Eric Beauchesne for his review.
In light of known weaknesses in specific TLS ciphersuites, many administrators want to reduce the set of available ciphersuites used by TLS 1.2 to a more secure subset.
The two main ways to set TLS ciphersuite policy in Windows are:
- Use Group Policy
- Use PowerShell
I am going to focus on the latter, and I tested this on Windows Server 2019 version 1809, current builds of Windows Server 2022, Windows 10 and Windows 11 will also work.
Use TLS 1.3
I want to stress that where possible, you need to use TLS 1.3, but sometimes, because of compatibility issues, you might not be able to, so you need to use TLS 1.2 with a more secure set of ciphersuites.
Selecting TLS 1.2 Ciphersuites
So, the first question is what determines a safer ciphersuite? For the answer I turned to NIST SP 800-52r2 (link) which describes preferred TLS 1.2 ciphersuites:
Section 3.3.1.1 “Cipher Suites for TLS 1.2 and Earlier Versions” states the following preferences when selection ciphersuites:
- Prefer ephemeral keys over static keys (i.e., prefer DHE over DH (Diffie Hellman), and prefer ECDHE over ECDH (Elliptic Curve Diffie Hellman)). Ephemeral keys provide perfect forward secrecy.
- Prefer GCM or CCM modes over CBC mode. The use of an authenticated encryption mode prevents several attacks (see Section 3.3.2 for more information). Note that these are not available in versions prior to TLS 1.2
Prefer CCM over CCM_8. The latter contains a shorter authentication tag, which provides a lower authentication strengths.
Using PowerShell
There’s a set of PowerShell cmdlets that can interrogate and set ciphersuites, they are documented here. We will use these cmdlets to change the ciphersuite settings on a Windows PC.
But before we get started, we need to change a registry setting to make sure the PowerShell changes take effect.
Load up regedit and delete this key.
HKEY_LOCAL_MACHINE\SOFTWARE\Policies\Microsoft\Cryptography\Configuration\SSL\00010002
I don’t think you need to reboot; I have tested with no reboot, and it all worked fine.
Now, let’s get a list of default ciphersuites. To do this, run:
Get-TlsCiphersuite | fw
And this is what you will see:
| TLS_AES_256_GCM_SHA384 TLS_AES_128_GCM_SHA256 TLS_ECDHE_ECDSA_WITH_AES_256_GCM_SHA384 TLS_ECDHE_ECDSA_WITH_AES_128_GCM_SHA256 TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA384 TLS_ECDHE_RSA_WITH_AES_128_GCM_SHA256 TLS_DHE_RSA_WITH_AES_256_GCM_SHA384 TLS_DHE_RSA_WITH_AES_128_GCM_SHA256 TLS_ECDHE_ECDSA_WITH_AES_256_CBC_SHA384 TLS_ECDHE_ECDSA_WITH_AES_128_CBC_SHA256 TLS_ECDHE_RSA_WITH_AES_256_CBC_SHA384 TLS_ECDHE_RSA_WITH_AES_128_CBC_SHA256 TLS_ECDHE_ECDSA_WITH_AES_256_CBC_SHA TLS_ECDHE_ECDSA_WITH_AES_128_CBC_SHA TLS_ECDHE_RSA_WITH_AES_256_CBC_SHA TLS_ECDHE_RSA_WITH_AES_128_CBC_SHA | TLS_RSA_WITH_AES_256_GCM_SHA384 TLS_RSA_WITH_AES_128_GCM_SHA256 TLS_RSA_WITH_AES_256_CBC_SHA256 TLS_RSA_WITH_AES_128_CBC_SHA256 TLS_RSA_WITH_AES_256_CBC_SHA TLS_RSA_WITH_AES_128_CBC_SHA TLS_RSA_WITH_3DES_EDE_CBC_SHA TLS_RSA_WITH_NULL_SHA256 TLS_RSA_WITH_NULL_SHA TLS_PSK_WITH_AES_256_GCM_SHA384 TLS_PSK_WITH_AES_128_GCM_SHA256 TLS_PSK_WITH_AES_256_CBC_SHA384 TLS_PSK_WITH_AES_128_CBC_SHA256 TLS_PSK_WITH_NULL_SHA384 TLS_PSK_WITH_NULL_SHA256 |
This is a list of all the supported ciphersuites in Window Server 2019 in preferred order. That’s a lot of ciphersuites!
You can get a list of ciphersuites available in various versions of Windows here.
The top two ciphersuites that start TLS_AES are TLS 1.3 only, note they only focus on the bulk encryption cipher (AES) and HMAC (SHA256 or SHA384), this was a big change made in TLS 1.3 to ciphersuite naming, the key exchange and certificate signature algorithms are set by the TLS 1.3 standard.
The rest are all TLS 1.2 only, and this is the set we’re going to update using PowerShell.
Using the NIST recommendations, we end up with this tiny list:
TLS_AES_128_GCM_SHA256
TLS_ECDHE_ECDSA_WITH_AES_256_GCM_SHA384
TLS_ECDHE_ECDSA_WITH_AES_128_GCM_SHA256
TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA384
TLS_ECDHE_RSA_WITH_AES_128_GCM_SHA256
I want to make it abundantly clear that this is an aggressive list, and you might have compatibility issues with some servers or clients. So, if some code fails to connect, you might need to add ciphersuites back to the list.
The really nice thing about using these PowerShell cmdlets to manipulate the ciphersuites is there is no need to reboot.
Here’s some sample code I wrote to reduce the list of ciphersuites:
set-strictmode -Version latest
$cs = Get-TlsCipherSuite
$csOk = 'TLS_AES_256_GCM_SHA384',
'TLS_AES_128_GCM_SHA256',
'TLS_ECDHE_ECDSA_WITH_AES_256_GCM_SHA384',
'TLS_ECDHE_ECDSA_WITH_AES_128_GCM_SHA256',
'TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA384',
'TLS_ECDHE_RSA_WITH_AES_128_GCM_SHA256'
foreach ($c in $cs) {
if ($csOk.Contains($c.Name)) {
$c.Name + ' Valid - Enable'
Enable-TlsCiphersuite -Name $c.Name
} else {
$c.Name + ' Disable'
try {
Disable-TlsCiphersuite -Name $c.Name
} catch {
$PSItem.Exception.Message
}
}
}
Basically, if a ciphersuite is not in the list $csOk, then the ciphersuite is disabled.
After running this, run Get-TlsCipherSuite one more time and you’ll see the reduced list. If you do not see a reduced list, then you did not purge the reg key I mentioned earlier!
From here on, any code that uses the Windows TLS settings (ie; schannel) will only use TLS 1.3 with two ciphersuites, and TLS 1.2 with four. If some code tries to connect with TLS 1.1, or TLS 1.2 using a ciphersuite not in the list, like TLS_RSA_WITH_3DES_EDE_CBC_SHA, it will fail.
Sometimes failures happen, and you might need to understand why. Thankfully, there is schannel logging which will let you know why it failed. This article Enable Schannel event logging in Windows – Internet Information Services | Microsoft Docs will explain how to set schannel logging and where to find the data. Set the value to 7 as this will give you failures and successes.
If you really are having a hard time working out why a connection fails, you could re-enable all the ciphersuites in the original list, attempt to connect and then look at the schannel log to see which ciphersuite was used. This code will set you back to normal without some of the cruft.
set-strictmode -Version latest
$cs = 'TLS_AES_256_GCM_SHA384',
'TLS_AES_128_GCM_SHA256',
'TLS_ECDHE_ECDSA_WITH_AES_256_GCM_SHA384',
'TLS_ECDHE_ECDSA_WITH_AES_128_GCM_SHA256',
'TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA384',
'TLS_ECDHE_RSA_WITH_AES_128_GCM_SHA256',
'TLS_DHE_RSA_WITH_AES_256_GCM_SHA384',
'TLS_DHE_RSA_WITH_AES_128_GCM_SHA256',
'TLS_ECDHE_ECDSA_WITH_AES_256_CBC_SHA384',
'TLS_ECDHE_ECDSA_WITH_AES_128_CBC_SHA256',
'TLS_ECDHE_RSA_WITH_AES_256_CBC_SHA384',
'TLS_ECDHE_RSA_WITH_AES_128_CBC_SHA256',
'TLS_ECDHE_ECDSA_WITH_AES_256_CBC_SHA',
'TLS_ECDHE_ECDSA_WITH_AES_128_CBC_SHA',
'TLS_ECDHE_RSA_WITH_AES_256_CBC_SHA',
'TLS_ECDHE_RSA_WITH_AES_128_CBC_SHA',
'TLS_RSA_WITH_AES_256_GCM_SHA384',
'TLS_RSA_WITH_AES_128_GCM_SHA256',
'TLS_RSA_WITH_AES_256_CBC_SHA256',
'TLS_RSA_WITH_AES_128_CBC_SHA256',
'TLS_RSA_WITH_3DES_EDE_CBC_SHA'
foreach ($c in $cs) {
try {
'Enabling ' + $c
Enable-TlsCiphersuite -Name $c
} catch {
$PSItem.Exception.Message
}
}
Please don’t judge me on the inclusion of 3DES_EDE_CBC_SHA in the list!
This code will raise an exception if it attempts to enable an already enabled ciphersuite, but the exception handler will make sure it keeps on trucking.
This is what a successful TLS connection looks like in the schannel log:
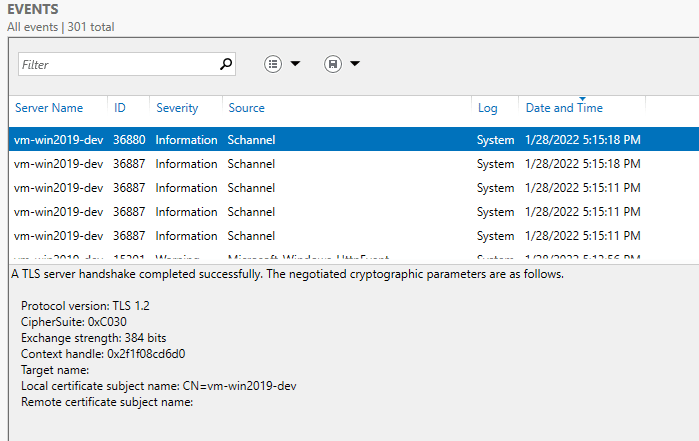
Note the ciphersuite – the name of the ciphersuite is not given, rather the value is used. 0xC030 is TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA384. You can see a complete list of these values here.
.NET TLS Coding Best Practices
One parting thought. If you have custom .NET code, and you set your TLS config in code please make sure you read this.
Many devs hard-code TLS 1.2 which means your code can NEVER use TLS 1.3. Rather than forcing TLS 1.2 in your code, you should offload the TLS configuration to Windows.
You will also make life easier for yourself if you target .NET 4.8 or .NET Core.
I realize this is a lot of material and quite complex, but I hope you find it useful. If there’s anything missing or not obvious, please let me know and I will address it.
– Michael